Получайте последние новости интернет-маркетинга.
А в качестве бонуса
дарим бесплатный чек-лист по аналитике.
Продвижение бизнеса в интернете
Пригласить в тендер
Закрыть

Применение машинного обучения в Google таблицах с помощью библиотеки Tensorflow.js и Google Apps скрипта
20 июля 9159 просмотров 4 минуты на чтение
Тема машинного обучения сейчас очень актуальна и продолжает набирать обороты. Машинное обучение — это алгоритм, с помощью которого система распознает данные и их закономерности, предсказывает значения на основе обученной модели.
Узнайте больше про сквозную и предиктивную аналитику. Посмотрите выпуск с руководителем отдела аналитики MediaNation Александром Вахтиным и аналитиком больших данных Романом Святовым:
К сожалению, осилить его применение на языках программирования в специальных интерфейсах не всегда просто, если ты не специалист. Поэтому мы решили перевести статью, которая послужит руководством применения машинного обучения в понятных Google таблицах.
В статье приведен пример использования кодов для предсказания новой величины на базе признаков, которые влияют на эту величину. Вы можете использовать приведенный алгоритм, например, если хотите предсказать число онлайн-покупок какого-то товара, если у вас есть данные по продажам за предыдущие периоды, а также показатели (числовые признаки), которые влияют на онлайн-покупки (например, число показов рекламы, число кликов, число заинтересованных посетителей, общее число посетителей, CTI, VTR, CTR, CTB и др.).
Кроме того, у статьи есть бонус - это тестовый файл (ссылка будет в конце), на котором вы сможете попрактиковаться.
Эта статья покажет вам, как вы можете настраивать, обучать и прогнозировать данные электронных таблиц с помощью фреймворка глубокого обучения Tensorflow.js. Вам не нужно вызывать REST API или использовать сторонние хранилища и алгоритм. Все ваши данные остаются в безопасной Google таблице.
Пример применения машинного обучения в Google таблицах:

Google недавно представил новый JavaScript runtime (V8 engine) в Google Apps скрипте.
Он усиливает платформу G Suite для новых вариантов использования автоматизации. Он заменяет старый Mozilla's Rhino JavaScript интерпретатор и позволяет вам включить современные библиотеки JavaScript.
TensorFlow изначально был для Python, но Google позже добавил поддержку большего количества языков программирования. (nodejs. JavaScript, Swift,..). Keras высокоуровневая нейронная сеть API наряду с TensorFlow. Она подходит для новичков и помогает строить нейронные сети. TensorFlow - это структура, основанная на JavaScript framework, для построения нейронных сетей и синтаксиса, который похож на Keras.
Тема машинного обучения является очень комплексной. Она содержит множество примеров использования, проектирования архитектур, настроек и небольших доработок.
Моя цель не в том, чтобы показать вам пошаговое учебное пособие, которое будет охватывать машинное обучение, а в том, чтобы вдохновить вас и показать вам еще одну точку зрения о возможностях сочетания Google таблиц и Google Apps скрипта.
Дисклеймер: Я прибег к небольшому взлому, чтобы подключить библиотеку Tensorflow.js. Я не могу гарантировать, что вы получите 100% точность результата.
Использование
Полагаю, у вас много данных в Google таблицах. Представьте сценарий, в котором на основе нескольких столбцов (с цифрами) вы хотите предсказать значение в последнем столбце. Это полезно, если вы хотите прогнозировать будущие значения из прошлых значений или некоторые значения отсутствуют, и вы можете заполнить пробелы. Этот сценарий называется многомерной регрессией.
Развертывание Tensorflow.js в Google Apps скрипте
Я скопировал всю библиотеку Tensorflow.js в однофайловый код в проект Google Apps скрипта как файл tf-js.gs.

Мне нужно было подготовить библиотеку Tensorflow.js перед тренировкой и предсказанями. Во-первых, библиотека использует имя global для глобальной переменной. Это было проще, потому что я только определил новую переменную и добавил новую строку кода:
Во-вторых, библиотека Tensorflow.js использует родные API "измерения времени" - в частности, Performance.now() или process.hrtime().
Performance.now() доступна только в API браузера (Chrome) и process.hrtime() доступна только в API языка бэкэнда (node.js). Появилась ошибка "Не могу измерить время в этой среде. Необходимо запустить tf.js в браузере или в Node.js" в Google Apps скрипте, потому что я не смог использовать первый и второй методы.
Я не полностью перепроектировал библиотеку, но думаю, что время измерения используется для получения основного потока для других задач. По этой причине я устанавливаю yieldEvery, что никогда не делал во время компиляции модели. (https://js.tensorflow.org/api/latest/)
Если у вас есть решения получше, напишите мне в Twitter или по электронной почте.
Данные
Набор данных Boston Housing Prices - это "hello world" входная задача в мир машинного обучения. Это коллекция из 500 простых записей о недвижимости, собранных в Бостоне (штат Массачусетс) в конце 1970-х годов. Каждая строка включает цифровые измерения района Бостона (например, уровень преступности, типичный размер домов, насколько данный район удален от ближайшей автомагистрали, есть ли в этом районе набережная...).
Эти столбцы названы как features(признаки) (=ввод в модель машинного обучения).
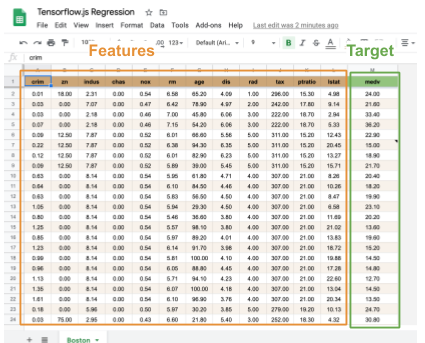
Мы хотим предсказать цену дома в соответствии с этим набором данных. Этот столбец - один и его название - target(цель) (=выход из модели машинного обучения).
Эта подготовленная функция загружает набор данных из Облачного хранилища Google напрямую в Google таблицу.
}
function loadCSV(type) {
let csv;
const BASE_URL = 'https://storage.googleapis.com/tfjs-examples/multivariate-linear-regression/data/';
csv = UrlFetchApp.fetch(BASE_URL + type.features).getContentText()
let features = Utilities.parseCsv(csv);
csv = UrlFetchApp.fetch(BASE_URL + type.target).getContentText()
let target = Utilities.parseCsv(csv)
let data = features.map((row, index) => {
row.push(target[index][0]);
return row
});
return data;
}
let sheet = SpreadsheetApp.getActiveSheet();
let trainRows = loadCSV(train);
let testRows = loadCSV(test);
let data = trainRows.concat(testRows);
sheet.getRange(sheet.getLastRow() + 1, 1, data.length, data[0].length).setValues(data);
} gas-load-boston-dataset.js на GitHub:Подготовка данных
Мы должны разделить данные на 2 группы: для обучения, для тестирования. Переменная rowSplit определяет номер строки для этого разделения. В нашем случае в качестве обучающего набора данных будут использоваться строки c 2 по 336. Остальные ряды (с 337 по 507) - в качестве тестового набора данных. Переменные FEATURE_COLUMN_FROM и FEATURE_COLUMN_TO определяют столбцы признаков для обучения, тестирования и прогнозирования. В нашем случае данные с признаками загружены в столбцы с 1 по 12.
function getData_(sheet) {
let data = { trainFeatures: [], trainTarget: [], testFeatures: [], testTarget: [], prediction: [] };
let range = sheet.getActiveRange();
//let labelColumn = range.getColumn();
let fromRow = range.getRow();
let toRow = fromRow + range.getNumRows() - 1;
Logger.log("Prediction rows: %s - %s", fromRow, toRow);
let values = sheet.getDataRange().getValues();
values.forEach((row, _index) => {
let rowIndex = _index + 1;
if (rowIndex === 1) return
let features = row.slice(FEATURE_COLUMN_FROM - 1, FEATURE_COLUMN_TO);
let label = row[TARGET_COLUMN - 1];
if (fromRow <= rowIndex && rowIndex <= toRow) {
data.prediction.push(features);
} else {
if (rowSplit <= rowIndex) {
data.testFeatures.push(features)
data.testTarget.push([label]);
} else {
data.trainFeatures.push(features);
data.trainTarget.push([label]);
}
}
});
Logger.log("Train: %s. Test: %s. Prediction: %s", data.trainFeatures.length, data.testFeatures.length, data.prediction.length);
return data;
}
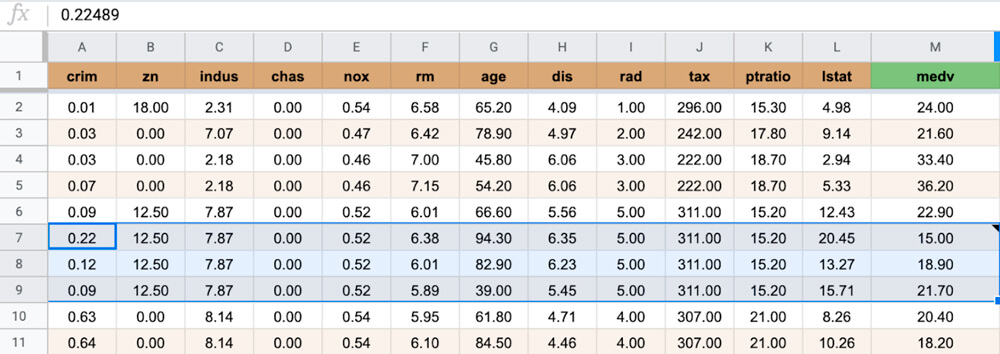
gas-tf-getData.js на GitHub: В качестве последнего шага выберите диапазон в Google таблице. Мы хотим оценить значения в столбце M в соответствии со значениями A- L в выбранных строках 7-9.
Tensorflow работает не со структурой данных Array, а с многомерными массивами данных. Функция createTensor() создает 2D многомерный массив данных.
function createTensor_(array) {
//Logger.log("shape[%s,%s]", array.length, array[0].length);
const tensor = tf.tensor2d(array, [array.length, array[0].length]);
return tensor;
}
gas-tf-createTensor.js на GitHub:Некоторые признаки (столбцы) содержат значения в разной шкале (например, значения налогов 187 - 711) по сравнению с другими (например, уровень преступности 0,01 - 88,98). Мы должны нормализовать и трансформировать значения, что улучшит производительность и тренировочную стабильность модели.
/**
* Calculates the mean and standard deviation of each column of an array.
*
* @param {Tensor2d} data Dataset from which to calculate the mean and
* std of each column independently.
*
* @returns {Object} Contains the mean and std of each vector
* column as 1d tensors.
*/
function determineMeanAndStddev_(data) {
const dataMean = data.mean(0);
const diffFromMean = data.sub(dataMean);
const squaredDiffFromMean = diffFromMean.square();
const variance = squaredDiffFromMean.mean(0);
const dataStd = variance.sqrt();
return { dataMean, dataStd };
}
/**
* Given expected mean and standard deviation, normalizes a dataset by
* subtracting the mean and dividing by the standard deviation.
*
* @param {Tensor2d} data: Data to normalize.
* Shape: [numSamples, numFeatures].
* @param {Tensor1d} mean: Expected mean of the data. Shape [numFeatures].
* @param {Tensor1d} std: Expected std of the data. Shape [numFeatures]
*
* @returns {Tensor2d}: Tensor the same shape as data, but each column
* normalized to have zero mean and unit standard deviation.
*/
function normalizeTensor_(data, dataMean, dataStd) {
return data.sub(dataMean).div(dataStd);
}
gas-tf-normalize.js hosted на GitHub:Создание модели и обучение
Как вы уже знаете, сети глубокого обучения содержат больше слоев с нейронами. Нам нужно определить архитектуру нейросети слой за слоем. Синтаксис подобен упомянутому Keras. У нас есть архитектура с двумя слоями, и каждый из них содержит 50 нейронов.
Здесь функции активации (Sigmoid) в каждом скрытом слое.
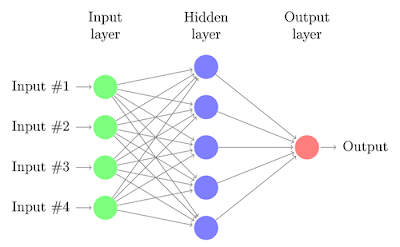
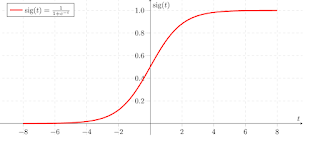
Последний слой содержит только один нейрон с функцией активации по умолчанию (линейной). Она линейная, потому что наш пример - регрессионный случай использования.
Следующий шаг - компиляция. На этом шаге нужно установить
- optimizer (оптимизатор) (стохастический градиентный спуск), как найти лучшее решение и веса нейрона
- loss function (функция потерь) (meanSquaredError), как измерить оптимальное решение
Теперь время для тренировок. Метод .fit() тренирует модель по данным в течение нескольких итераций (=EPOCHS).
Эти значения, такие как количество эпох, количество слоев, количество нейронов, тип функции активации являются гиперпараметрами. Специалисты по данным по всему миру настраивают эти значения и сравнивают их с предыдущими настройками.
Подробнее о настройках в Tensorflow.JS API https://js.tensorflow.org/api/latest/.
/*
Создать нейросеть
*/
async function createModel_(features, target) {
const model = tf.sequential();
model.add(tf.layers.dense({units: 50, activation: "sigmoid", kernelInitializer: 'leCunNormal', inputShape: [features.shape[1]] }));
model.add(tf.layers.dense({units: 50, activation: "sigmoid", kernelInitializer: 'leCunNormal',}));
model.add(tf.layers.dense({units: 1}));
model.compile({
optimizer: tf.train.sgd(LEARNING_RATE),
loss: tf.losses.meanSquaredError,
metrics: ['mae']
});
let trainLoss;
let valLoss;
var history = await model.fit(features, target, {
batchSize: BATCH_SIZE,
epochs: EPOCHS,
validationSplit: 0.2,
yieldEvery: "never",
callbacks: {
onEpochEnd: async (epoch, logs) => {
trainLoss = logs.loss;
valLoss = logs.val_loss;
console.log(`Epoch ${epoch + 1} / ${EPOCHS}. Train loss: ${trainLoss}`);
}
}
});
return { model, trainLoss, valLoss };
}
gas-tf-createModel.js на GitHub:Оценка позволяет проверить точность вашей модели. Чем меньше потерь, тем лучше. Вы должны сравнить потери при обучении с потерями при тестировании. Большие потери обучения означают Переобучение. Это не идеально.
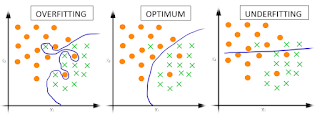
Предсказание
Когда мы довольны качеством нашей модели и величина потерь - оптимальна, можно предсказывать значения признаков. Также необходимо преобразовать значения предсказания массива в многомерные массивы данных и нормализовать.
В нашем коде фрагмент прогнозируемых значений сохраняется в ячейке Notes, и вы можете сравнить его с исходными значениями.
Это главная функция, которая загружает, подготавливает, тренирует данные.
async function main() {
let sheet = SpreadsheetApp.getActiveSpreadsheet().getActiveSheet()
let data = getData_(sheet);
let trainFeatures = createTensor_(data.trainFeatures);
let trainTarget = createTensor_(data.trainTarget);
let testFeatures = createTensor_(data.testFeatures);
let testTarget = createTensor_(data.testTarget);
//computeBaseline_(trainTarget, testTarget);
let { dataMean, dataStd } = determineMeanAndStddev_(trainFeatures); // Normalize mean standard
trainFeatures = normalizeTensor_(trainFeatures, dataMean, dataStd);
testFeatures = normalizeTensor_(testFeatures, dataMean, dataStd);
let ml = await createModel_(trainFeatures, trainTarget);
const evalResult = ml.model.evaluate(testFeatures, testTarget, { batchSize: BATCH_SIZE })
const testLoss = evalResult[0].dataSync()[0];
console.log(`Train-set loss: ${ml.trainLoss.toFixed(4)}\n\tValidation-set loss: ${ml.valLoss.toFixed(4)}\n\tTest-set loss: ${testLoss.toFixed(4)}`);
let predictionFeatures = createTensor_(data.prediction);
predictionFeatures = normalizeTensor_(predictionFeatures, dataMean, dataStd);
let result = ml.model.predict(predictionFeatures).dataSync();
Logger.log("Prediction: %s", result);
let values= Object.keys(result).map( index => [result[index]]);
let range = sheet.getActiveRange();
sheet.getRange( range.getRow(),range.getLastColumn(), values.length, 1 ).setNotes(values)
}
gas-tf-main.js наGitHub:Попробуйте самостоятельно!
Если вы хотите протестировать и поиграть, полный набор данных + код Google Apps скрипта доступен в этом разделе Google таблицы.
- Создайте копию таблицы
- Выберите любой из рядов (последнее значение будет пропущено во время тренировки).
- Откройте меню Инструменты --> Редактор сценариев (Script editor)
- Выберите меню "Запустить" --> "Запустить функцию" и выберите "Главное"
- Прогнозируемые значения будут сохранены в виде примечаний.
Если вам нравится Google Apps скрипт, такие люди, как вы, находятся в этом сообществе Google Groups community.
Оригинальная статья:
https://www.kutil.org/2020/05/machine-learning-in-google-sheet.html
Другие статьи по теме
09 июля 2043 просмотра 7 мин
.png)
28 августа 3373 просмотра 3 мин

23 июня 3145 просмотров 15 минут
.jpg)
27 июня 13062 просмотра 7 минут
Выгрузка данных из Яндекс.Директ с указанием условия подбора (корректировки) трафика
Зачастую перед аналитиком встает задача глубокого исследования данных о производительности рекламных кампаний в Яндекс.Директе.

21 июня 11702 просмотра 15 минут

05 апреля 5883 просмотра 7 минут

30 декабря 4028 просмотров 15 минут
.jpg)
15 октября 8408 просмотров 7 минут

08 октября 6134 просмотра 7 минут

17 сентября 58150 просмотров 7 минут
Что такое веб-аналитика и как настроить веб-аналитику для сайта
Почти все сайты подключены к системам Яндекс.Метрики и Google Analytics. Счетчики установлены, отчеты создаются. Правда, во многих случаях аналитика заканчивается именно на этом этапе. Как организовать действительно эффективную работу по веб-аналитике сайта и сделать ее важной частью бизнеса – в нашем лонгриде.

Подпишитесь на новости
и получите чек-лист по аналитике
и получите чек-лист по аналитике
Наверх