Продвижение бизнеса в интернете
Пригласить в тендер
Закрыть

Визуальный анализ данных RFM-сегментации
19 ноября 6273 просмотра 7 минут на чтение


Существует тип людей, которых принято называть визуалами. У них активна зрительно-ассоциативная функция мозга, поэтому поступающую информацию проще воспринимается через изображения, графики, таблицы и т.п. Статистика говорит о том, что к данному типу людей относится 80-85% жителей нашей планеты.
Порой именно графики помогают определить некие закономерности между различными показателями. Построить их можно не только вручную, но и автоматически благодаря знаниям программирования. Для тех, кто слаб в данной сфере, предлагаем действовать по инструкции, указанной в статье.
Мы построим графики на основе результатов RFM-анализа. Они помогут понять, сколько клиентов находится в каждом из сегментов, сколько ежедневно осуществлялось покупок, зависимость заказов от выручки и другие. Ранее в блоге MediaNation было описано, как грамотно произвести RFM-анализ на языке программирования Python. Продолжим знакомиться с его возможностями.
Узнайте больше про сквозную и предиктивную аналитику. Посмотрите выпуск с руководителем отдела аналитики MediaNation Александром Вахтиным и аналитиком больших данных Романом Святовым:
Подготовительный этап
Для начала определим, какие файлы и программы пригодятся для построения графиков.
Что должно быть на компьютере перед началом работы:- Программный пакет Anaconda (версии 3 и выше)
- Программа Jupyter Notebook
- Библиотека RFMizer
- Библиотека Plotly
- Файлы RFM-анализа
- Файл выгрузки из CRM в формате csv
Первым делом необходимо запустить Anaconda Navigator и программу Jupyter Notebook.
В открывшейся вкладке браузера кликаем по команде “New” и выбираем Python.
Перед нами открывается командная строка, в которой будут прописываться все предложенные в статье команды. Для их активации кликаем по кнопке “Run”.
- исходного order.csv - файл выгрузки из CRM
- RFM_3-3-3-365-182_mapping.csv - файл, полученный в результате проведения RFM-анализа благодаря RFMizer.
Далее в статье будут указана последовательность команд, которые необходимо прописать в командной строке для построения соответствующих графиков. Для визуализации данных можно использовать множество библиотек на Python, но наиболее удобной нам кажется Plotly. Перед началом создания каждого из графиков необходимо произвести импорт библиотеки и включить оффлайн мод:
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
import plotly.graph_objs as go
import pandas as pd
from plotly.subplots import make_subplots
Ниже прописываем указанные команды.
Создание графика количества заказов по дням
#активируем библиотеку на Юпитере
init_notebook_mode(connected=True)
#обращаемся к исходному файлу
df = pd.read_csv('/Users/ivanbarchenkov/Documents/rfm-test/orders.csv')
#агрегируем данные для построения графика
count_order_date_df = df.groupby('order_date', as_index = False).user_id.count()
#задаем оси и значения
trace = go.Bar(
x = count_order_date_df.order_date,
y = count_order_date_df.user_id
)
#указываем название диаграммы
layout = go.Layout(
title='Заказы по дням',
)
#выводим график
fig = go.Figure(data = [trace], layout = layout)
iplot(fig)
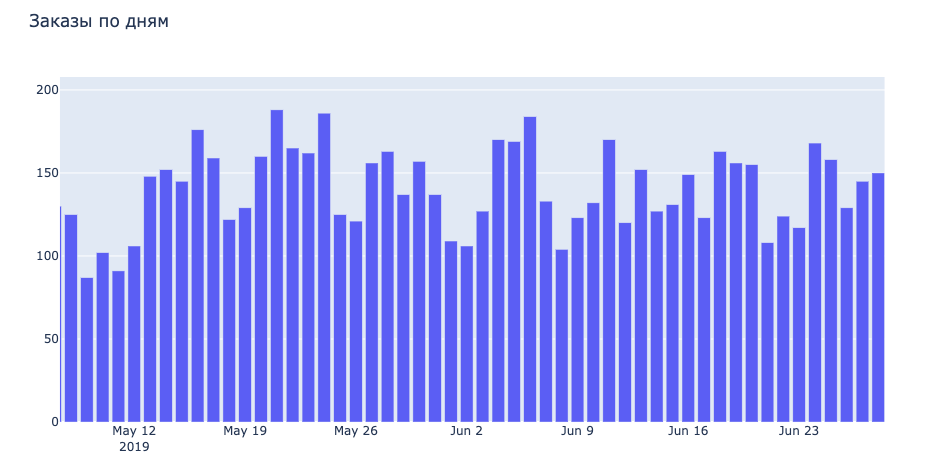
В результате получим наглядную статистику по количеству ежедневных заказов.
Создание графика ежедневной выручки
count_order_date_df = df.groupby('order_date', as_index = False).order_value.sum()
trace = go.Bar(
x = count_order_date_df.order_date,
y = count_order_date_df.order_value
)
layout = go.Layout(
title='Выручка по дням',
)
fig = go.Figure(data = [trace], layout = layout)
iplot(fig)
Результат:
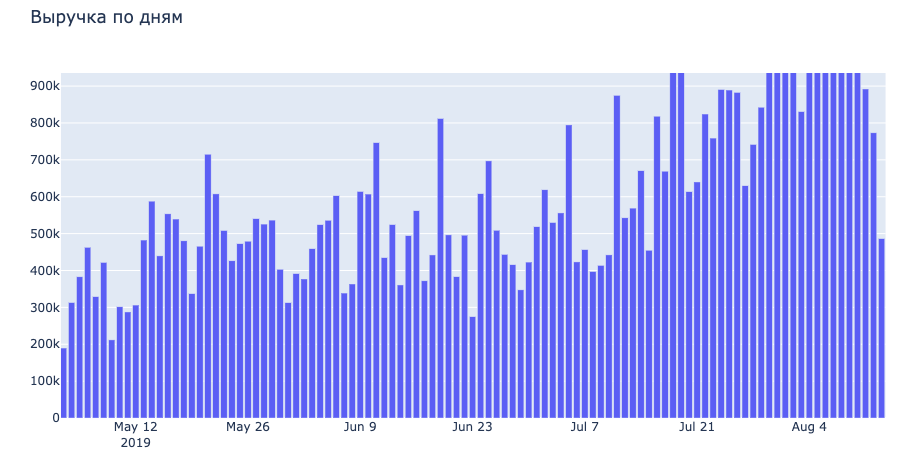
Создание графика зависимости заказов и выручки
compare_userid_df = df.groupby('order_date', as_index = False).user_id.count()
compare_value_df = df.groupby('order_date', as_index = False).order_value.sum()
fig = make_subplots(specs=[[{"secondary_y": True}]])
fig.add_trace(
go.Scatter(
x = compare_userid_df.order_date,
y = compare_userid_df.user_id,
name = 'Заказы'
),
secondary_y=False
)
fig.add_trace(
go.Scatter(
x = compare_value_df.order_date,
y = compare_value_df.order_value,
name = 'Выручка'
),
secondary_y=True
)
fig.update_layout(
title_text="Заказы и выручка по дням"
)
# Set x-axis title
fig.update_xaxes(title_text="Дни")
# Set y-axes titles
fig.update_yaxes(title_text="Заказы", secondary_y=False)
fig.update_yaxes(title_text="Выручка", secondary_y=True)
fig.show()
Результат:
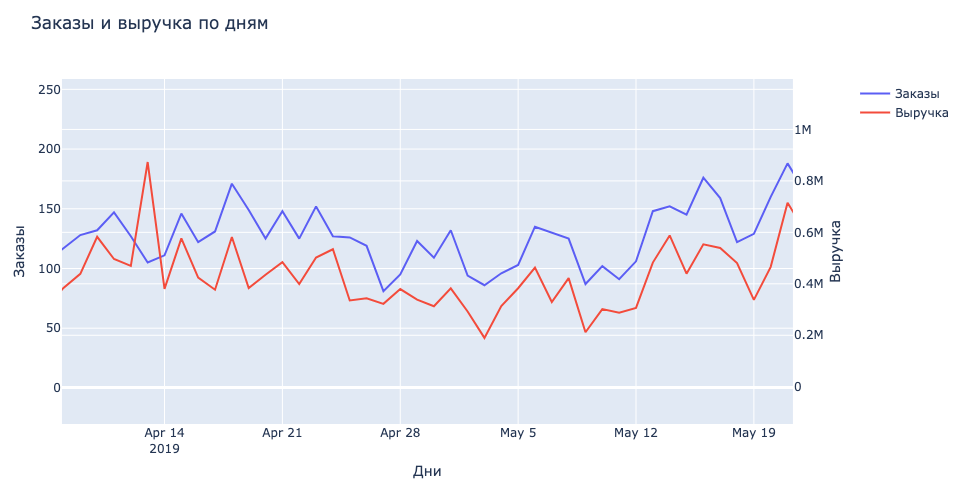
Создание графика количества клиентов в каждом из сегментов R, F, M
count_frequency_df = df.groupby('frequency', as_index = False).user_id.count()
count_monetary_df = df.groupby('monetary', as_index = False).user_id.count()
count_recency_df = df.groupby('recency', as_index = False).user_id.count()
trace_frequency = go.Bar(
x = count_frequency_df.frequency,
y = count_frequency_df.user_id,
name = 'frequency'
)
trace_monetary = go.Bar(
x = count_monetary_df.monetary,
y = count_monetary_df.user_id,
name = 'monetary'
)
trace_recency = go.Bar(
x = count_recency_df.recency,
y = count_recency_df.user_id,
name = 'recency'
)
layout = go.Layout(
title='Количество пользователей внутри RFM',
)
fig = go.Figure(data = [trace_frequency, trace_monetary, trace_recency], layout = layout)
iplot(fig)
Результат:
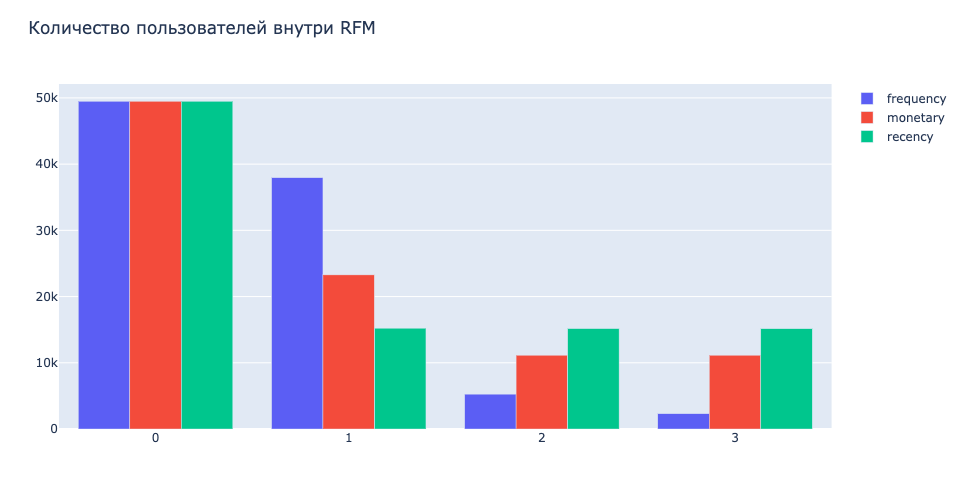
Создание графика для изучения соотношения сегментов
Данные этого графика пригодятся, чтобы в дальнейшем понять какие RFM-сегменты необходимо объединить между собой в целях создания загружаемого файла для Яндекс.Аудиторий или любых других сервисах.
Напоминаем!
В Яндекс.Аудитории должно быть загружено минимум 1000 записей.
Если в сегменте нет нужного количества пользователей, то следует либо объединить между собой пользователей из разных сегментов, либо переделать RFM-анализ с меньшим количеством сегментов.
import plotly.express as px
tips = df.groupby(['frequency', 'recency','monetary'], as_index = False).user_id.count()
fig = px.scatter(tips, x="frequency", y="recency", color="user_id", size='user_id', facet_col="monetary",
render_mode="webgl")
fig.update_yaxes(dtick=1) #делаем шаг оси равный 1
fig.show()
Результат:
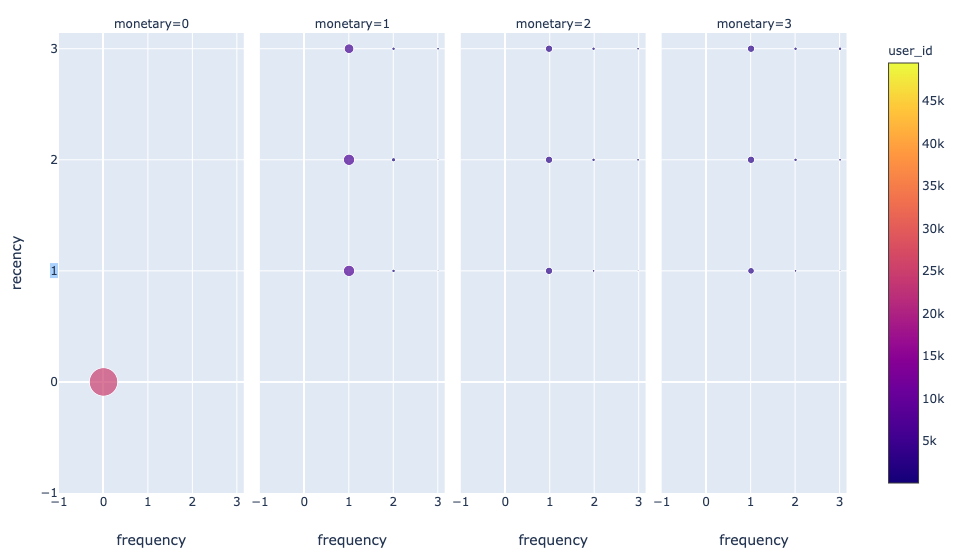
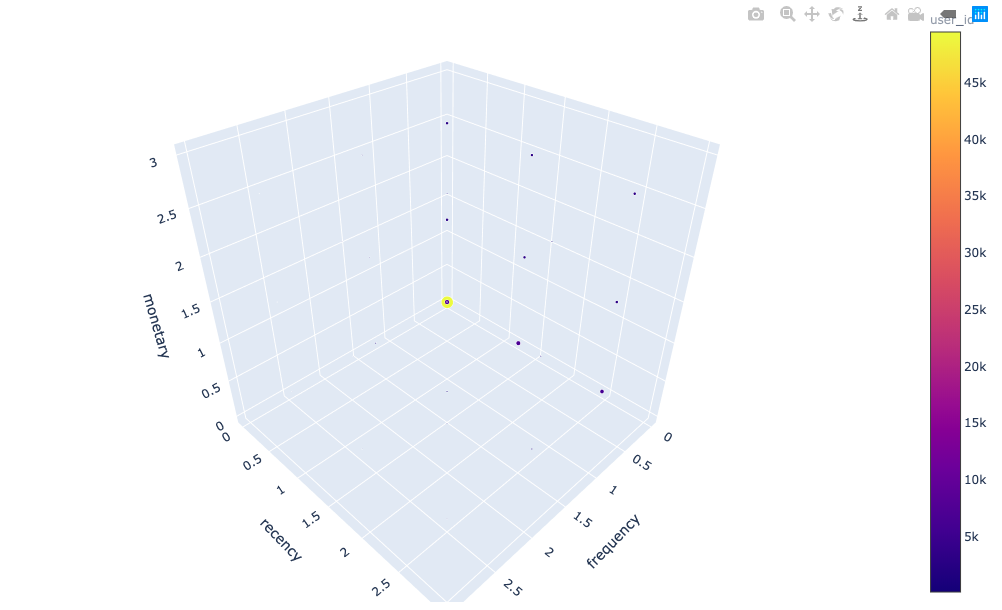
Создание 3D графика
Для любителей 3D предлагаем следующую визуализацию:
tips = df.groupby(['frequency', 'recency','monetary'], as_index = False).user_id.count()
fig = px.scatter_3d(tips, x='frequency', y='recency', z='monetary',
color='user_id', size='user_id', opacity=1)
# tight layout
fig.update_layout(margin=dict(l=0, r=0, b=0, t=0))
fig.show()
Результат:
Потребительский рынок динамичен, поэтому требует постоянного совершенствования маркетинговых стратегий. Визуализация статистики рекламных кампаний, финансовых показателей бизнеса, покупательской активности позволяет произвести более глубокий анализ своей деятельности и взглянуть на ее результаты под иным углом. Это, в свою очередь, поможет ускорить процесс поиска новых и оптимальных идей. Кроме этого, если клиент требует наглядно продемонстрировать динамику эффективности рекламной кампании, то данная статья поможет вам автоматизировать процесс построения графиков и сократить время на выполнение поставленной задачи.
Другие статьи по теме
09 июля 2535 просмотров 7 мин
.png)
28 августа 3553 просмотра 3 мин

23 июня 3366 просмотров 15 минут
.jpg)
27 июня 15356 просмотров 7 минут
Выгрузка данных из Яндекс.Директ с указанием условия подбора (корректировки) трафика
Зачастую перед аналитиком встает задача глубокого исследования данных о производительности рекламных кампаний в Яндекс.Директе.

21 июня 12099 просмотров 15 минут

05 апреля 6153 просмотра 7 минут

30 декабря 4288 просмотров 15 минут
.jpg)
15 октября 8671 просмотр 7 минут

08 октября 6379 просмотров 7 минут

17 сентября 59272 просмотра 7 минут
Что такое веб-аналитика и как настроить веб-аналитику для сайта
Почти все сайты подключены к системам Яндекс.Метрики и Google Analytics. Счетчики установлены, отчеты создаются. Правда, во многих случаях аналитика заканчивается именно на этом этапе. Как организовать действительно эффективную работу по веб-аналитике сайта и сделать ее важной частью бизнеса – в нашем лонгриде.

Наверх