Продвижение бизнеса в интернете
Пригласить в тендер
Закрыть

Автоматизация RFM-анализа: как сегментировать клиентскую базу на Python
14 ноября 13080 просмотров 7 минут на чтение


RFM-анализ позволяет направлять маркетинговые ресурсы в нужном направлении благодаря сегментации клиентской базы по трем основным показателям потребительского поведения:
R - recency — давность (как давно ваши клиенты что-то покупали);
F - frequency — частота (как часто клиенты покупают);
M - monetary — деньги (общая сумма покупок).
Существует несколько способов проведения RFM-анализа. Все они отличаются уровнем автоматизации и денежными вложениями. В данной статье мы рассмотрим наиболее оптимальный способ - RFM-анализ с помощью языка программирования Python.
Преимущества способа:
На самом деле, работа с Python легче, чем может показаться на первый взгляд. А если учесть, что в статье приводится поэтапная настройка RFM-анализа, то задача по силам даже начинающему маркетологу.
Сегментация по RFM
В результате за каждым клиентом будет закреплено трехзначное число. Например, 213 - сегмент покупателей, относительно недавно (2) совершивших разовую покупку (1) с высоким чеком (3).
С помощью таблицы в Microsoft Excel можно разбить клиентов по сегментам вручную. Но если база состоит из нескольких сотен тысяч уникальных покупателей, но разумнее прибегнуть к автоматизации процесса.
Для облегчения данной задачи рекомендуем скачать и установить программу Anaconda. Версии для Windows, MacOS и Linux доступны по ссылке https://www.anaconda.com/distribution/ .
Шаг 3. Установить пакет pyyaml и plotly.
Заходим в Anaconda-Navigator в раздел Environment (окружение). В правом поле ввода поискового запроса указываем наименование искомых файлов. Получив результат поиска, нажимаем на пакет и кликаем по кнопке Apply.
На изображении пример с другим пакетом, который еще не установлен
Подготовительная часть перед работой с Python завершена. Следующий этап - настройка библиотеки RFMizer.
Шаг 1. Зайти в папку, в которую распаковано содержимое архива RFMizer. Открыть файл config.yaml.
Шаг 2. Установить текстовый редактор, поддерживающий плагины на языке Python.
Следующие операции подразумевают редактирование файла config.yaml. Для этого лично мы применяем программу Sublime Text.
Если у вас установлен другой текстовый редактор, поддерживающий плагины на языке Python, скачивать Sublime Text не обязательно.
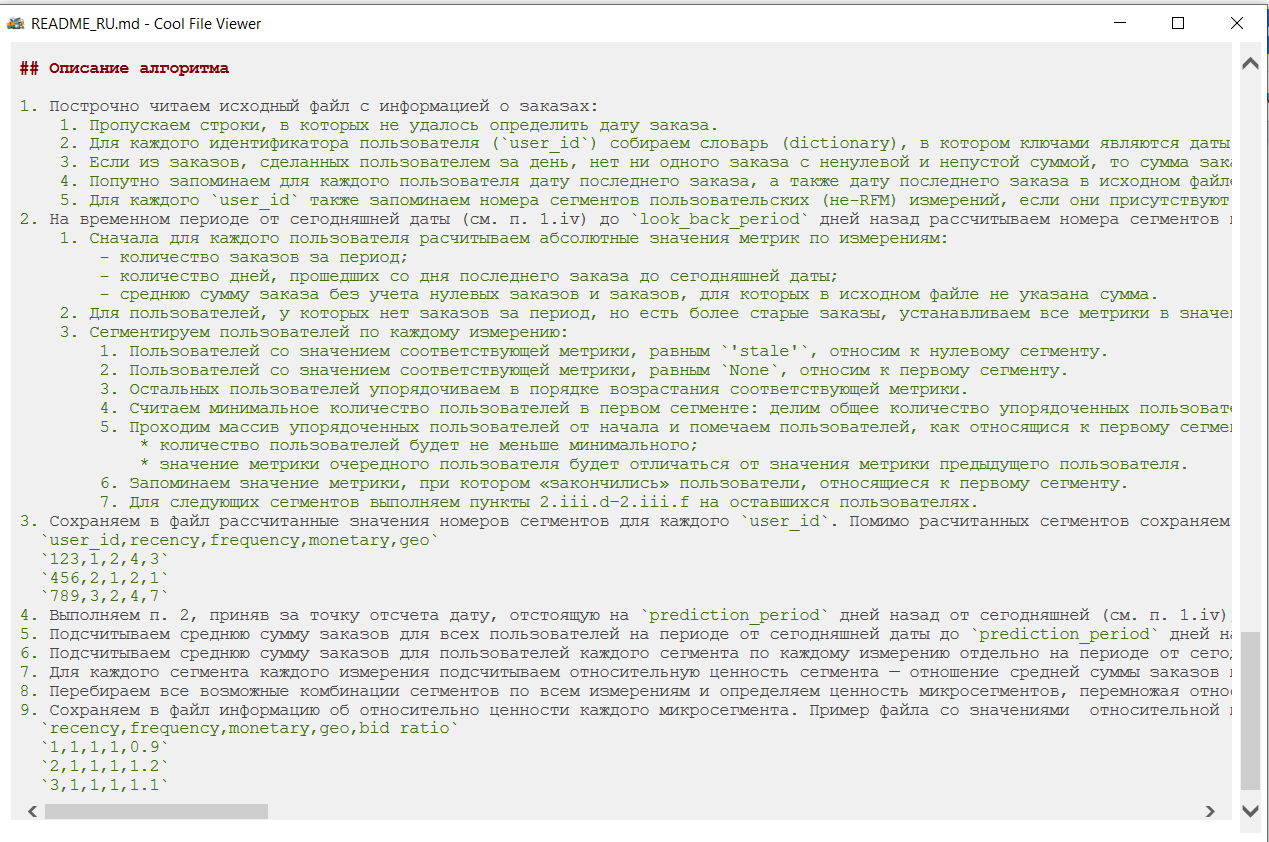
В конце файла readme.txt прописан алгоритм работы RFMizer’а. Поклонникам программирования будет интересно с ним ознакомиться. Если вы не из их числа, то пропустить данный раздел не страшно.
Последний параметр команды input-file - это название файла из CRM. Чтобы было проще, советуем переименовать файл в orders.csv. Тогда команда будет выглядеть так: python rfmizer.py config.yaml orders.csv
Новые файлы получили такое название, потому что в config.yaml в параметре output_file_prefix было указано RFM_3-3-3-365-182.
RFM_3-3-3-365-182_mapping.csv - текстовый CSV-файл, в котором каждая строка состоит из четырех обязательных полей и произвольного количества необязательных полей (например, параметры географической принадлежности места совершения заказа или любые другие параметры, которые интересны).
R - recency — давность (как давно ваши клиенты что-то покупали);
F - frequency — частота (как часто клиенты покупают);
M - monetary — деньги (общая сумма покупок).
Существует несколько способов проведения RFM-анализа. Все они отличаются уровнем автоматизации и денежными вложениями. В данной статье мы рассмотрим наиболее оптимальный способ - RFM-анализ с помощью языка программирования Python.
Преимущества способа:
- Автоматизация процесса сегментации по RFM.
- Возможность работы с многотысячной (объемной) клиентской базой.
- Бесплатный инструмент для проведения RFM-анализа.
- Может показаться сложным для специалистов, не имевших дело с программированием.
На самом деле, работа с Python легче, чем может показаться на первый взгляд. А если учесть, что в статье приводится поэтапная настройка RFM-анализа, то задача по силам даже начинающему маркетологу.
Узнайте больше про сквозную и предиктивную аналитику. Посмотрите выпуск с руководителем отдела аналитики MediaNation Александром Вахтиным и аналитиком больших данных Романом Святовым:
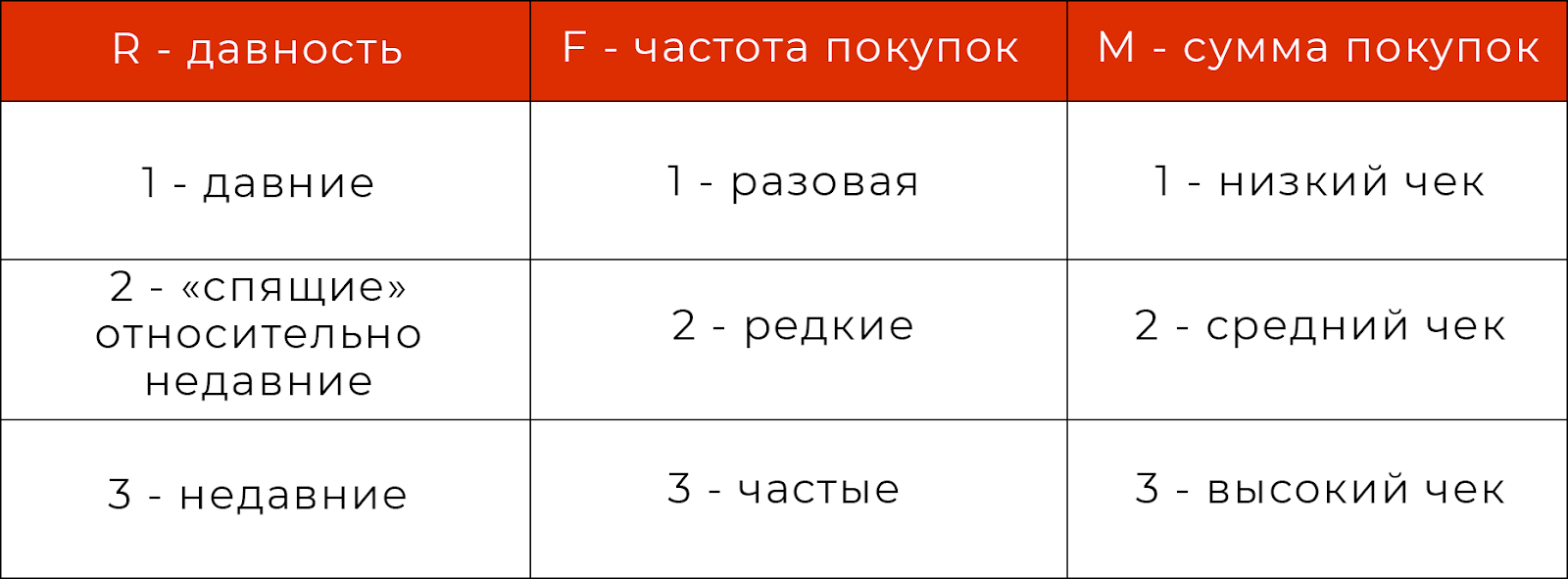
Принцип RFM-сегментации
RFM-анализ производится на основе выгрузки из системы учета/CRM/ERP или excel. Каждого клиента базы данных за исследуемый период необходимо распределить по соответствующим сегментам. Для этого в группах recency, frequency и monetary определим еще по три категории (для более детального анализа их может быть больше), обозначив цифрами от 1 до 3.
Сегментация по RFM
В результате за каждым клиентом будет закреплено трехзначное число. Например, 213 - сегмент покупателей, относительно недавно (2) совершивших разовую покупку (1) с высоким чеком (3).
В нашем случае все клиенты будут распределены по 27 сегментам. Это позволит направлять digital-инструменты на более узкую аудиторию, а не целиться рекламой на общую массу клиентов с разными целями и отношением к бренду.
С помощью таблицы в Microsoft Excel можно разбить клиентов по сегментам вручную. Но если база состоит из нескольких сотен тысяч уникальных покупателей, но разумнее прибегнуть к автоматизации процесса.
Python для автоматизации RFM-анализа
Для автоматизации RFM-анализа потребуется библиотека RFMizer на языке программирования Python. Она была создана сотрудником Google Александром Приходько и размещена по ссылке https://github.com/Slony/rfmizer.
Предоставляем пошаговую инструкцию для запуска скрипта.
Подготовительный этап
Шаг 1. Скачать архив библиотеки RFMizer и распаковать его.
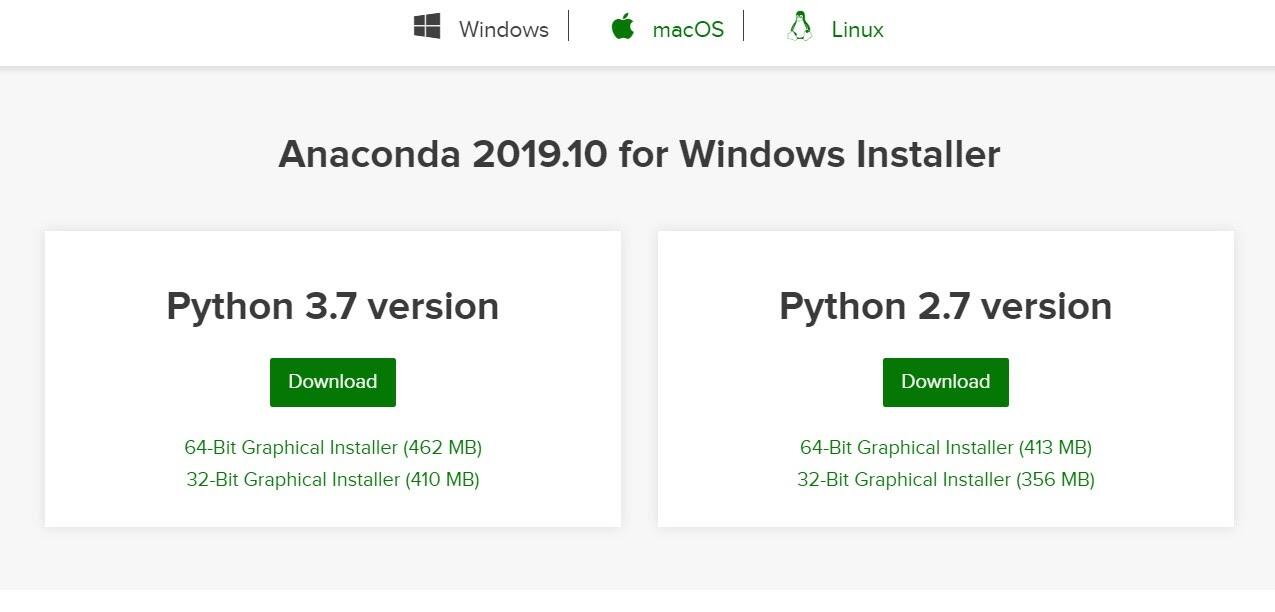
Шаг 2. Установить язык программирования Python, точнее его интерпретатор версии 3 и выше.Для облегчения данной задачи рекомендуем скачать и установить программу Anaconda. Версии для Windows, MacOS и Linux доступны по ссылке https://www.anaconda.com/distribution/ .
Выбираем версию Python 3.7 version (доступна на момент статьи) или выше
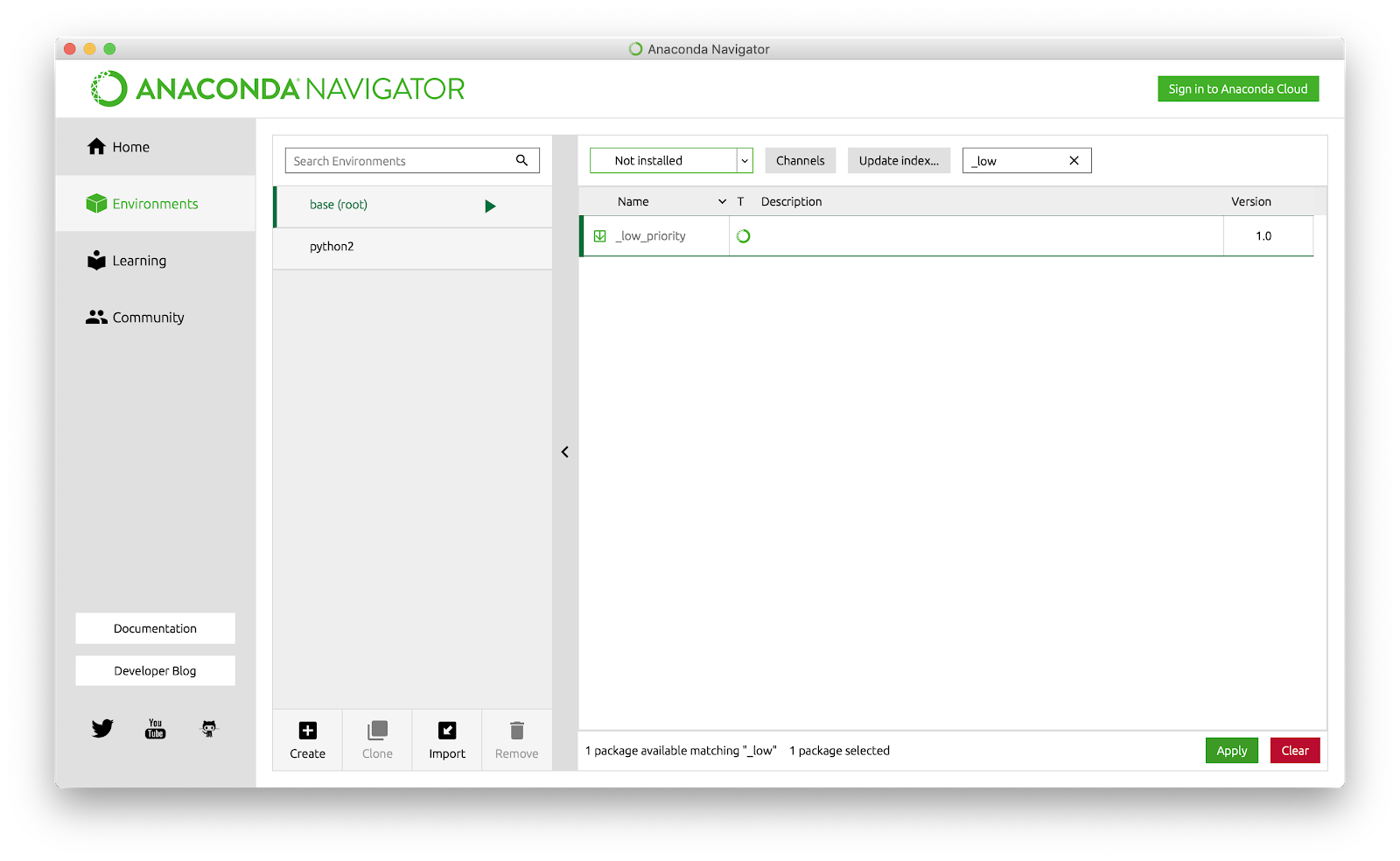
Шаг 3. Установить пакет pyyaml и plotly.
Заходим в Anaconda-Navigator в раздел Environment (окружение). В правом поле ввода поискового запроса указываем наименование искомых файлов. Получив результат поиска, нажимаем на пакет и кликаем по кнопке Apply.
На изображении пример с другим пакетом, который еще не установлен
Подготовительная часть перед работой с Python завершена. Следующий этап - настройка библиотеки RFMizer.
Настройка RFMizer
RFMizer - это библиотека на языке Python, которая позволяет автоматизировать процесс произведения RFM-анализа. На данном этапе необходимо обозначить собственные показатели для последующего запуска скрипта.
Шаг 1. Зайти в папку, в которую распаковано содержимое архива RFMizer. Открыть файл config.yaml.
Шаг 2. Установить текстовый редактор, поддерживающий плагины на языке Python.
Следующие операции подразумевают редактирование файла config.yaml. Для этого лично мы применяем программу Sublime Text.
Если у вас установлен другой текстовый редактор, поддерживающий плагины на языке Python, скачивать Sublime Text не обязательно.
Шаг 3. Подставить в файл config.yaml данные для RFM-анализа.
Внутри файла config.yaml вместо строк-подсказок подставляем собственные значения или значения клиента.
- количество сегментов в каждом из параметров Recency, Frequency, Monetary (в нашем случае три)
- период, за который делается анализ look_back_period
- значения предсказания prediction_period
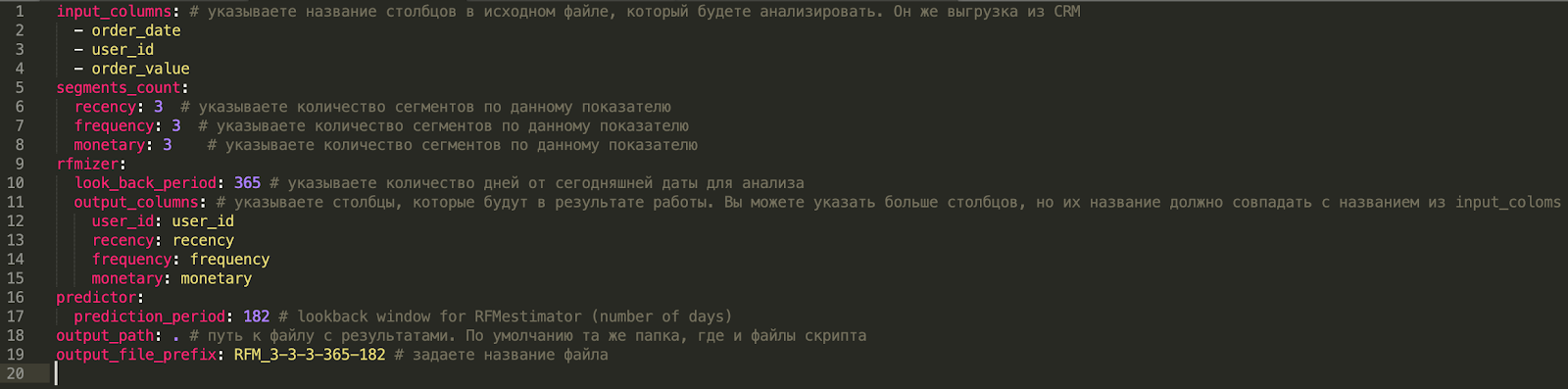
Ниже приводим содержимое файла в текстовом виде:
input_columns: # указываете название столбцов в исходном файле, который будете анализировать. Он же выгрузка из CRM
- order_date
- user_id
- order_value
segments_count:
recency: 3 # указываете количество сегментов по данному показателю
frequency: 3 # указываете количество сегментов по данному показателю
monetary: 3 # указываете количество сегментов по данному показателю
rfmizer:
look_back_period: 365 # указываете количество дней от сегодняшней даты для анализа
output_columns: # указываете столбцы, которые будут в результате работы. Вы можете указать больше столбцов, но их название должно совпадать с названием из input_coloms
user_id: user_id
recency: recency
frequency: frequency
monetary: monetary
predictor:
prediction_period: 182 # lookback window for RFMestimator (number of days)
output_path: . # путь к файлу с результатами. По умолчанию та же папка, где и файлы скрипта
output_file_prefix: RFM_3-3-3-365-182 # задаете название файла
Шаг 4. Сохранить измененный файл.
Шаг 5. Добавить в папку со скриптом файл выгрузки из CRM.
Выгрузка из CRM должна содержать следующие столбцы:- order_date
- user_id
- order_value
Важно!
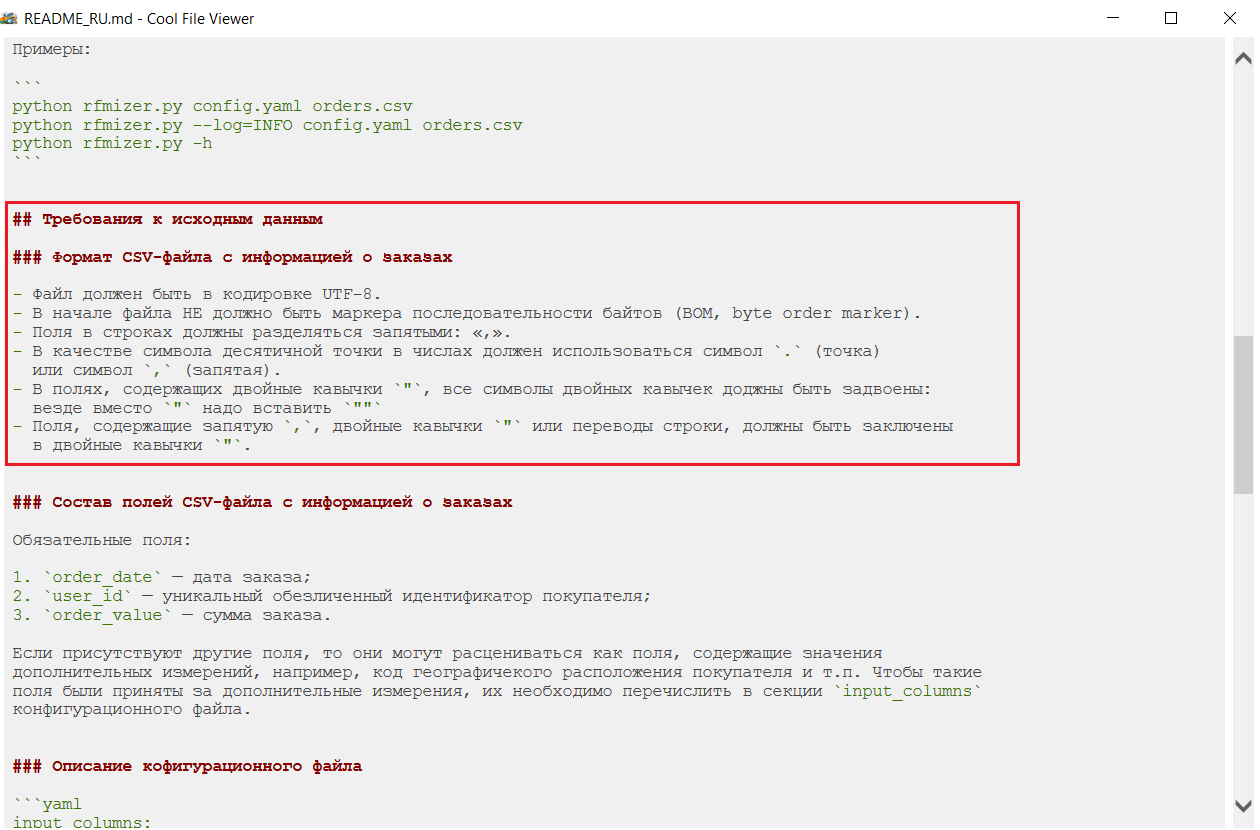
Необходимо соблюдать требования к файлу из CRM (формат csv). Все они обозначены в документе readme.txt (файл также доступен по ссылке https://github.com/Slony/rfmizer), содержащемся в библиотеке RFMizer.
Выдержка из файла readme.txt
- Файл должен быть в кодировке UTF-8
- В начале файла не должно быть маркера последовательности байтов (BOM, byte order marker).
- Поля в строках должны разделяться запятыми: «,».
- В качестве символа десятичной точки в числах должен использоваться символ `.` (точка) или символ `,` (запятая).
- В полях, содержащих двойные кавычки `"`, все символы двойных кавычек должны быть задвоены: везде вместо `"` надо вставить `""`
- Поля, содержащие запятую `,`, двойные кавычки `"` или переводы строки, должны быть заключены в двойные кавычки `"`.
В конце файла readme.txt прописан алгоритм работы RFMizer’а. Поклонникам программирования будет интересно с ним ознакомиться. Если вы не из их числа, то пропустить данный раздел не страшно.
Запуск скрипта
Для запуска скрипта требуется выполнить команду python rfmizer.py config.yaml input-file
Сделать это необходимо из папки, в которой находится файл.
На заметку!Последний параметр команды input-file - это название файла из CRM. Чтобы было проще, советуем переименовать файл в orders.csv. Тогда команда будет выглядеть так: python rfmizer.py config.yaml orders.csv
Шаг 1. Выполнить команду pwd в командной строке для определения директории. Получаем ответ /Users/ibarchenkov.
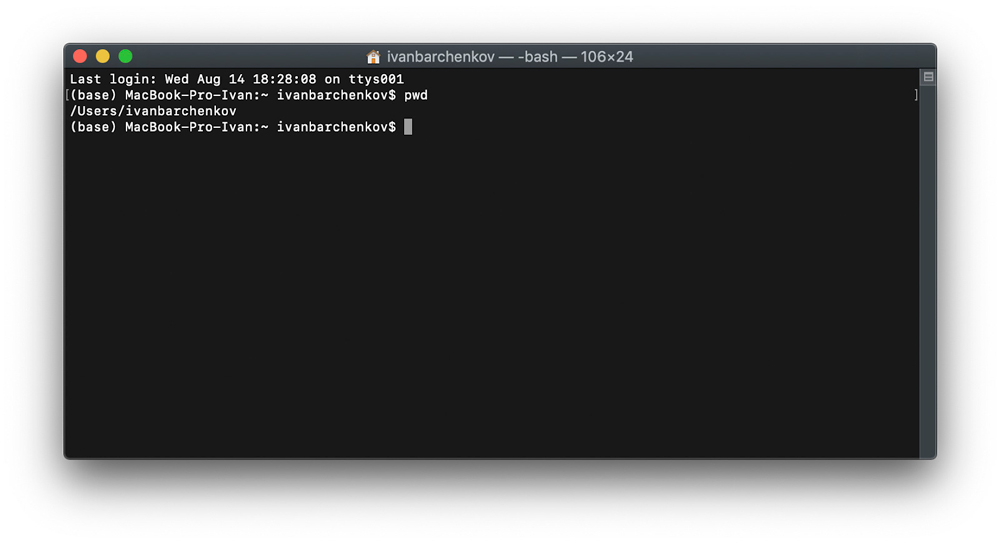
Шаг 2. Выполнить команду для перехода в папку со скриптом.
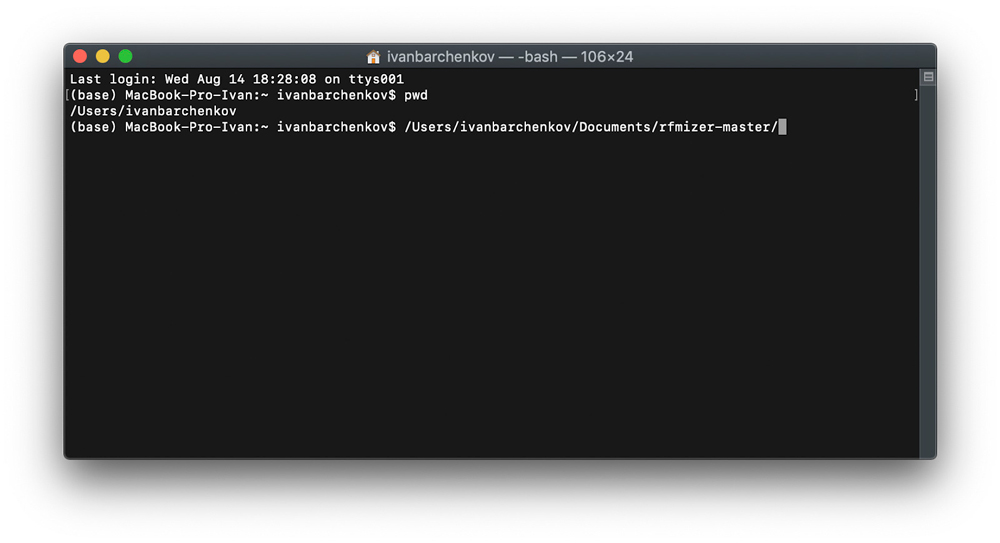
После нажатия “Ввод” последует смена директории и запуск скрипта.
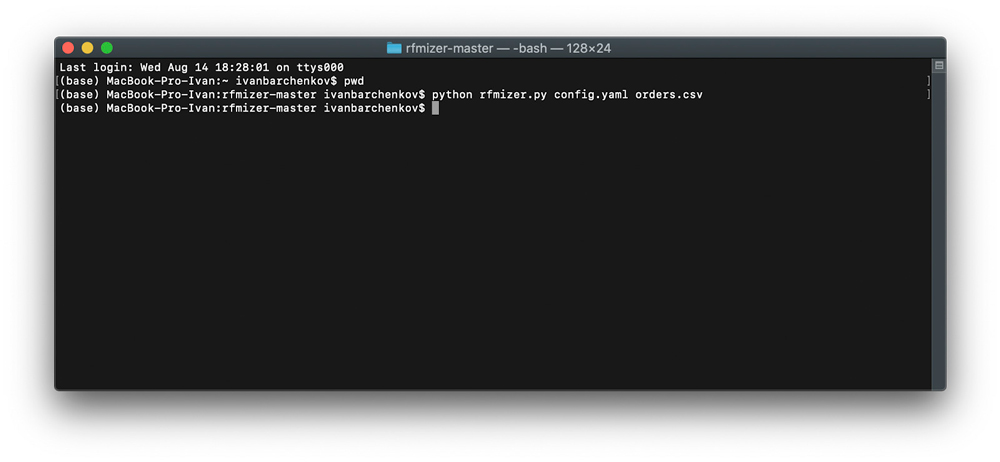
В результате в папке со скриптом появятся три файла:
- RFM_3-3-3-365-182_borders.csv
- RFM_3-3-3-365-182_mapping.csv
- RFM_3-3-3-365-182_ratios.csv
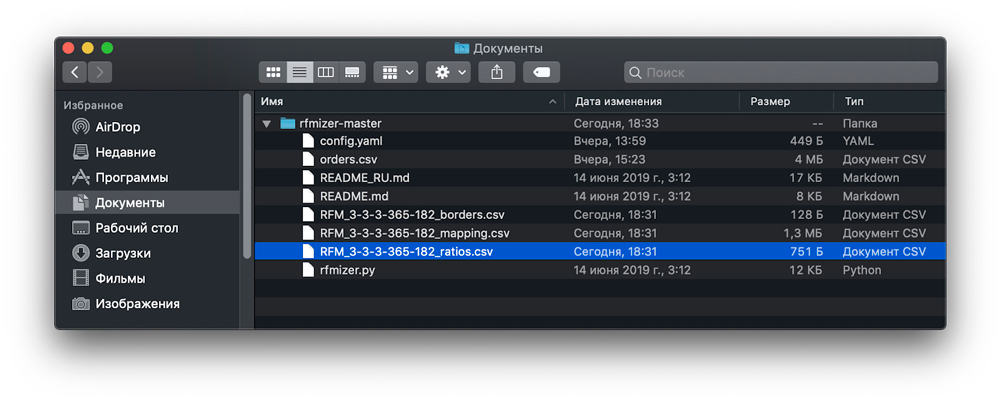
Напомним!
Новые файлы получили такое название, потому что в config.yaml в параметре output_file_prefix было указано RFM_3-3-3-365-182.
Обзор результата работы скрипта
RFM_3-3-3-365-182_borders.csv - это текстовый файл в формате CSV, который содержит числовые значения вычисленных границ между сегментами. С большой долей вероятности вы не будете никак работать с данным файлом
Пример содержимого файла:
dimension,segment,border
frequency,1,2
frequency,2,3
frequency,3,4
frequency,4,6
monetary,1,23.7
monetary,2,35.95
monetary,3,51.0
monetary,4,82.0
recency,1,-252
recency,2,-192
recency,3,-137
recency,4,-80
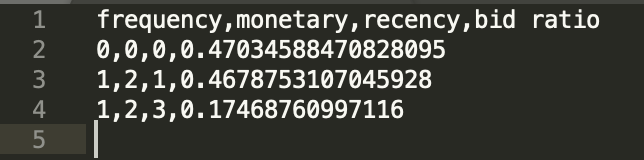
RFM_3-3-3-365-182_mapping.csv - текстовый CSV-файл, в котором каждая строка состоит из четырех обязательных полей и произвольного количества необязательных полей (например, параметры географической принадлежности места совершения заказа или любые другие параметры, которые интересны).
Это наиболее важный файл. Он позволяет соединить результаты RFM-анализа и персональные данные пользователя, которые в последующем нужны для работы в рекламных системах.
Обязательными являются поля:- user_id - внутренний идентификатор пользователя в CRM-системе (берется из исходного файла).
- Новизна (recency) - условно, давность последнего заказа
- Частота (frequency) - сегмент измерения частоты заказа
- Доходность (monetary) - денежное измерение
Пример содержимого файла:
user_id,recency,frequency,monetary,geo
274223,1,3,4,1
826746,2,2,1,5
734242,4,1,2,7
RFM_3-3-3-365-182_ratios.csv - файл содержит большое количество строк.
Количество строк должно быть равно следующему числу 1 (строка с названием столбцов) + R*F*M + 1 (строка с значением 0,0.0). Получаем 29 строк.
Пример нескольких строк файла:
Наибольший интерес в данном файле представляет столбец bid ratio. Bid ratio является мультипликатором ставки для каждого из пересечений сегментов пользователей, который создает скрипт RFMizer. Это означает, что если ранее ставка для закупки трафика была равна 10 рублям, то при работе с отдельными сегментами, например для сегмента 1,2,1, ставку 10 рублей необходимо умножить на мультипликатор 0,47 (значение округлено до сотых).
Применять данные полученного RFM-анализа можно в любых рекламных сервисах при проведении ремаркетинговой кампании или для формирования исключающих списков аудитории. Но важно помнить, что они требуют регулярного обновления, т.к. аудитория покупателей пребывает в постоянной динамике. Насколько часто это приходится делать, зависит от специфики бизнеса. Например, для крупного интернет-магазина с широким ассортиментом обновление списков и новый RFM-анализ можно проводить один в месяц. Учитывая, что теперь вы освоили процесс автоматизации, сделать это будет не сложно. Особенно после пары повторений.
Коллеги, приходите к нам за услугой аналитики для бизнеса!
Другие статьи по теме
09 июля 2651 просмотр 7 мин
.png)
28 августа 3627 просмотров 3 мин

23 июня 3436 просмотров 15 минут
.jpg)
27 июня 16518 просмотров 7 минут
Выгрузка данных из Яндекс.Директ с указанием условия подбора (корректировки) трафика
Зачастую перед аналитиком встает задача глубокого исследования данных о производительности рекламных кампаний в Яндекс.Директе.

21 июня 12198 просмотров 15 минут

05 апреля 6245 просмотров 7 минут

30 декабря 4357 просмотров 15 минут
.jpg)
15 октября 8745 просмотров 7 минут

08 октября 6442 просмотра 7 минут

17 сентября 59621 просмотр 7 минут
Что такое веб-аналитика и как настроить веб-аналитику для сайта
Почти все сайты подключены к системам Яндекс.Метрики и Google Analytics. Счетчики установлены, отчеты создаются. Правда, во многих случаях аналитика заканчивается именно на этом этапе. Как организовать действительно эффективную работу по веб-аналитике сайта и сделать ее важной частью бизнеса – в нашем лонгриде.

Наверх