Продвижение бизнеса в интернете
Пригласить в тендер
Закрыть

Решающий момент: модели атрибуции и как с ними работать
05 февраля 5549 просмотров 7 минут на чтение


В Google Analytics мы можем посмотреть, сколько раз пользователь взаимодействовал с сайтом, при помощи каких каналов он на него попал и как эта цепочка в итоге завершилась. Но как понять, какой именно канал принес продажу? Здесь помогут модели атрибуции.
Узнайте больше про сквозную и предиктивную аналитику. Посмотрите выпуск с руководителем отдела аналитики MediaNation Александром Вахтиным и аналитиком больших данных Романом Святовым:
Представим следующую цепочку. Мы «поймали» пользователя при помощи контекстной рекламы, он пришел на сайт, оставил свою почту. Он ушел, но через некоторое время его «догнали» при помощи email-маркетинга. Пользователь вернулся на сайт, ушел с него, потом снова вернулся через запрос в поиске и снова ушел. Мы вернули его ремаркетингом, он посетил сайт, ушел, а через некоторое время вернулся на сайт, и он, наконец, совершил покупку.
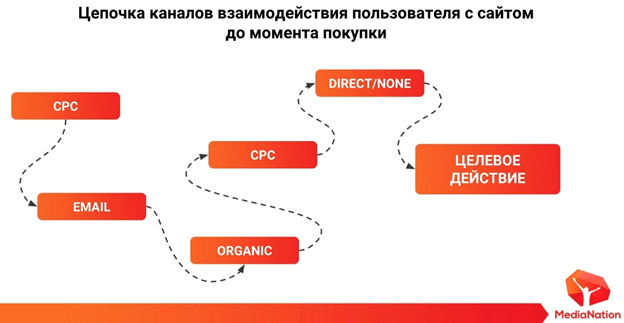
В этой ситуации возникает вопрос: какой же из каналов в действительности считать ценным? Ответ могут дать модели атрибуции. Модель атрибуции – это набор правил, которые определяют ценность рекламных каналов на пути к конверсии.
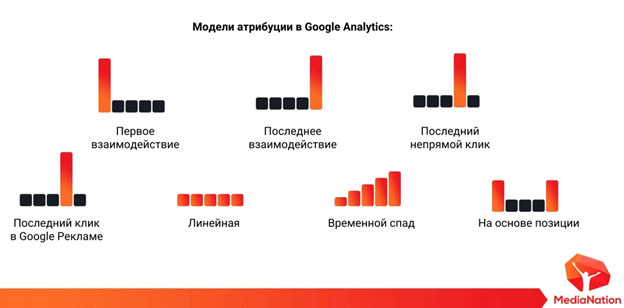
Моделей атрибуции в Google Analytics достаточно много. В основной массе отчетов используется модель, которая называется последний непрямой клик. Что это значит? Если мы разложим цепочку коммуникации с пользователем сайта, то мы получим, что последний непрямой клик атрибутирует целевое действие (заявку, транзакцию, заказ), которое идет за один шаг до direct/none (прямой заход на сайт или из «закладок»).
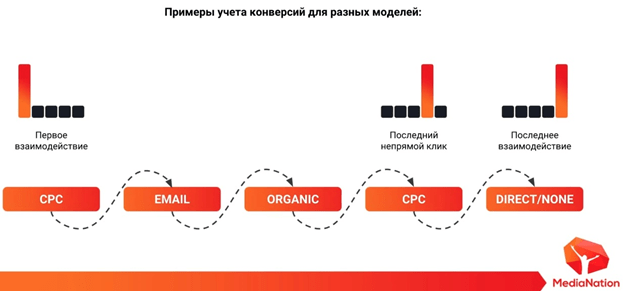
Мы привели пользователя через рекламу, «догнали» его email-рассылкой, SEO. Он пришел к нам на сайт, ушел, снова вернулся. В самом конце пользователь совершил целевое действие, и мы эту транзакцию атрибутировали только четвертому (в данном примере) каналу в очереди. На этом этапе ряд бизнесов начинает делать не совсем верные выводы. Решив, что этот четвертый канал приносит большое количество транзакций, они повышают по нему ставки, игнорируя другие каналы. А это неправильно.
Есть и другая логика, которую мы можем построить из модели под названием первое взаимодействие. В этой модели транзакция атрибутируется первому рекламному каналу вне зависимости от того, насколько длинной была цепочка взаимодействия пользователя с сайтом, из скольких шагов она состояла и сколько времени она заняла. Правильно ли это? Тоже нет. Человек пришел на сайт один раз, и без email-рассылок, ремаркетинга и других рекламных каналов он вряд ли бы снова вспомнил об сайте.
Зеркальное отражение предыдущей модели – модель последнее взаимодействие, когда транзакция атрибутируется последнему касанию. И здесь тоже есть некоторая смысловая ошибка. До direct/non пользователь доходит через какую-то определенную цепочку каналов. Он может запомнить адрес сайта из-за email-рассылки и ввести его в браузерную строку. Либо на него может повлиять контекстная реклама или ремаркетинг. В этом случае мы можем сделать предположение, что данная модель также не описывает реального положения дел и реального вклада каждого канала в то, что человек совершил какую-то транзакцию и принес в конечном итоге прибыль для компании.
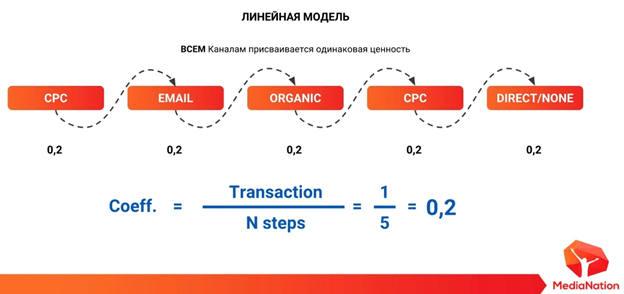
Следующая модель – линейная. Она берет то количество денег (целевых действий), которое принес пользователь в рамках данной цепочки, и делит их на количество шагов в рамах данной цепочки. Получается, что все каналы между собой уравниваются. Например, у нас была одна транзакция и пять шагов. Соответственно, 0,2 дохода от транзакции мы атрибутируем на каждый канал в этой цепочке. И снова вопрос: как нам правильно распределять рекламный бюджет? Ведь все каналы между собой усредняются. Кроме того, возможны цепочки и короче. Модель не будет реально отражать эффективность бизнеса. Мы не сможем принимать правильные решения относительно того, как правильно распределить рекламные бюджеты между разными каналами.
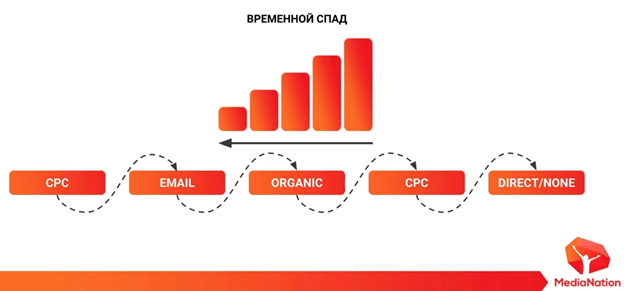
Еще одна модель – временной спад. Наибольшую ценность получает канал, который находится последним в цепочке, а наименьшую ценность канал, который находится в цепочке первым. Получается, что максимальный вес мы отдадим каналу direct/non. Но это не рекламный канал, и мы не можем перераспределить на него рекламные деньги и как-либо повлиять на него.
И наконец та, модель, на которой необходимо остановиться подробнее – модель атрибуций на основе позиций. Создать ее можно кастомно.
Суть заключается в том, Google Analytics позволяет задать по умолчанию некую ценность, которую вы хотите атрибутировать на канал, который изначально привел пользователя. Далее у нас есть последний канал, который клиента «дожал». Ему тоже присваивается такая же ценность, как и первому. Остается некоторое промежуточное звено, которое состоит в нашем случае из трех каналов. По умолчанию можно присвоить усредненное значение ценности.
Но опять сложность. Последним снова является direct/non, на который мы повлиять не можем. Здесь на помощь нам приходит создание сложных правил и условий, которые сочетаются между собой операторами И/ИЛИ. Например, мы можем указать, что на первый канал у нас приходится ценность в 40%, на промежуточное звено – 20%, на последний канал – 40%. Но если последнее взаимодействие – это direct/non, то в этом случае мы ему присваиваем ему нулевую ценность. Таким образом, последнее взаимодействие в рамках данной конкретной цепочки сместится на шаг влево, и мы получим более-менее понятную картинку. Здесь мы должны посмотреть, какие каналы были до брендового и начать увеличивать ставки именно на эти рекламные каналы, так как они будут увеличивать количество запросов бренда в поисковых системах.
В чем подвох?
В каждом бизнесе существует определенный срок, в течение которого пользователь принимает решение о покупке. Например, для сферы недвижимости, это может быть целый год. И тут в работе с Google Analytics может возникнуть проблема: вся цепочка взаимодействий с пользователем записывается только в течение 90 дней. Что делать в таком случае? Выгружать данные с Google Analytics во внешнее хранилище, хранить все эти данные на срок работы с клиентом и затем строить атрибуционные модели самостоятельно. С их помощью удастся понять, в какой рекламный канал необходимо инвестировать деньги, чтобы в рамках срока принятия решения о покупке количество транзакций и, соответственно, доход, увеличивались.
Модели атрибуций в деле
MediaNation использовали модели атрибуции в рамках работы над увеличением продаж интернет-магазина мебели TheFurnish. Мы выгрузили из Google Analytics данные по всем цепочкам, которые приводили пользователя к покупке, и поняли, что в среднем пользователям нужно около 80 дней на принятие решения. Таким образом, внутренние отчеты Analytics нам подошли, и выгружать данные во внешнее хранилище не было необходимости.

Далее мы расписали рекламные каналы в рамках всех этих цепочек и распределили вес и ценность каждого канала. Все это было сделано при помощи атрибуционной модели на основе позиций. После принятия решений мы выгрузили новые ставки и бюджеты тех рекламных кампаний, которых мы раньше не замечали и считали неэффективными. Мы уменьшили вес брендовых запросов, трафика с рассылок, трафика с прямых заходов, а также расширили окно оценки эффективности с 30 до 90 дней.
Результат. Уже через квартал мы увидели следующее: за счет правильного распределения рекламного бюджета доход клиента увеличился на 20 %.
Советы вместо вывода
Постарайтесь отходить от базовых отчетов Яндекс.Метрики и Google Analytics, которые показывают не совсем приближенные к жизни атрибуционные модели.
Перестаньте думать об эффективности каждого конкретного канала, потому что зацикленность на KPI и урезание одних каналов приводит к тому, что другие каналы начинают работать хуже.
Необходимо помнить, что всю цепочку взаимодействий с пользователем Google Analytics записывает только в течение 90 дней. Если срок принятия решения о покупке больше, то данные нужно выгружать во внешнее хранилище.
Другие статьи по теме
09 июля 2514 просмотра 7 мин
.png)
28 августа 3545 просмотров 3 мин

23 июня 3356 просмотров 15 минут
.jpg)
27 июня 15167 просмотров 7 минут
Выгрузка данных из Яндекс.Директ с указанием условия подбора (корректировки) трафика
Зачастую перед аналитиком встает задача глубокого исследования данных о производительности рекламных кампаний в Яндекс.Директе.

21 июня 12084 просмотра 15 минут

05 апреля 6144 просмотра 7 минут

30 декабря 4279 просмотров 15 минут
.jpg)
15 октября 8662 просмотра 7 минут

08 октября 6365 просмотров 7 минут

17 сентября 59237 просмотров 7 минут
Что такое веб-аналитика и как настроить веб-аналитику для сайта
Почти все сайты подключены к системам Яндекс.Метрики и Google Analytics. Счетчики установлены, отчеты создаются. Правда, во многих случаях аналитика заканчивается именно на этом этапе. Как организовать действительно эффективную работу по веб-аналитике сайта и сделать ее важной частью бизнеса – в нашем лонгриде.

Наверх